Description
将输入的一组数据用链表的形式按输入顺序存储起来,将其进行转置之后输出。要求使用递归的方式实现链表的转置。
Input 先输入正整数n(n>0),代表接下来输入的数据的个数。然后输入一组大小为n的数据(均为整数)。
Output Sample Input 1
5 15 20 30 1 6 Sample Output 1
6 1 30 20 15 Sample Input 2
1 78 Sample Output 2
78
Sample Input 3
10 1 2 3 4 5 6 7 8 9 40
Sample Output 3
40 9 8 7 6 5 4 3 2 1
分析: 首先题目要求我们使用链表。那么我们自然要先定义一个链表类。在这里我们忽略删除,插入等等常规操作。仅仅定义了输入使用的append和输出使用的traverse(遍历),以及题目所要求的的reserved和相关的reserve_link事实上链表类可以是先定义一个Node类,再定义一个Link类,然后链表的每个节点是一个Node,也可以不定义一个Link类,但给Node类一个函数,称之为create_link,这个函数返回的就是链表的head即可。
(这里插个题外话,之所以变量名和函数名都采用这种下划线的形式而非大写字母,是因为pycharm提醒我这样才符合python的规范)
承上,这里采用第一种做法,额外定义一个Link类。其中__init__()是类的初始化函数,self指代的就是类(该实例)本身。另外,为了方便,除了常规的头结点,我们牺牲一点空间,用一个len来保存Link的长度,再有一个tail指向最后一个节点(按照我的理解,tail是绑定在了最后一个节点上,不额外消耗空间,可能有误)对于代码中的其他细节,这里不再赘述,进入正题。
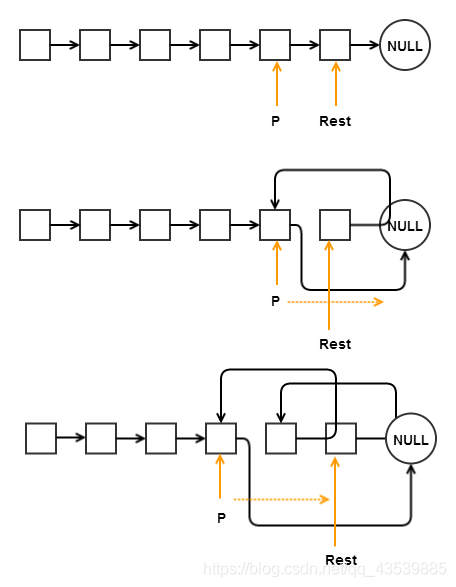
我们先关注reverse_link(),这是一段类似于c写法的代码。 原理是: 首先我们传入了某段链表(Link)和一个Head(这里不单单是元素无意义的节点 而是指某段链表的第一个节点 事实上为了链表方便性而生的头结点有时候会成为一个麻烦)。如果Head是空则返回空,Head是尾(无下一个节点则返回Head),很好理解,返回Head自然是为了方便递归,保持输入输出的一致性。然后让我们跳过head_node = self.reverse_link(head.next_node)这一句,先看下面的内容: head.next_node.next_node = head head.next_node = None
使得head的下一个节点的下一个节点是它本身,读起来有点拗口,但是可以知道的是这一步完成了让Head和Head的下一个节点之间的链接反转的小任务(关键)。
然后head自己指向的下一个节点为空,这里不理解没关系。我们现在知道的是,每次进入这个函数,我们会让传进去的这个Head的下一个节点成为它的上一个节点。体会到了吗,只要我们让这个过程从初始链表的头部开始进行,那么我们就能完成整个链表的反转。为此,我们需要reverse_link()里加入reverse_link(),它的输入应该是head.next_node,而且我们可以立即知道如果一切像我们想象地发展,那么内层的这个reverse_link()返回的应该是从尾部开始的已经反转好的一段链表的尾部(这里的尾部指的是离原始链表尾部最远的一端),此时我们用一个head_node把这个节点存起来。 存起来干嘛呢?你会发现在我们刚刚讨论中根本没有用到这个值,因此,这个值的作用非常简单,就是推动递归的进程,让递归向着边界条件前进,不至于出不来。 刚刚说过head自己指向的下一个节点为空,有的同志可能会说,那我不是丢了下一个节点的位置吗。其实这里因为我们是递归的结构,相当于把函数一层层放到栈里,因此每次压栈时内存里给我们保存了每一个head(每一个原始列表里的节点)的位置,
所以我们每次出栈,也就是从列表的后头往前走,就会自动得到前一个节点(head),而这个head和后一个节点的链接是还没断的,我们在前一次里让前一个head的next_node为none其实是断了已经处理好的链表的最后一个节点。